Forrest Iandola -- Bio and Example Application
Homework 0
Bio:
My name is Forrest Iandola, and I'm a 1st year PhD student in EECS. I have some background in parallel programming, distributed systems, and computer vision. One of my current research interests lies in accelerating and composing common computational kernels on parallel hardware.Goals for this class:
In this class, I aim to build up a deep understanding of theoretical aspects of parallel computing. For example, I'm interested in learning more about lower bounds on communication and parallel computational complexity.Application where parallel programming has been used:
Communication-Minimizing 2D Image Convolution in GPU Registers
This is a quick overview of some of my recent joint work with David Sheffield, Michael Anderson, Mangpo Phothilimthana, and Kurt Keutzer. This work uses NVIDIA Fermi and Kepler GPUs.
2D image convolution is ubiquitous in image processing and computer vision problems. For feature extraction algorithms like Histogram of Oriented Gradients (HOG), and in other applications of edge detection, convolving with small filters (e.g. 2x2–7x7) is common. Exploiting parallelism is a common strategy for accelerating convolution.
Parallel processors keep getting faster, but algorithms such as image convolution remain memory bounded on parallel processors such as GPUs. Therefore, reducing memory communication is fundamental to accelerating image convolution. To reduce memory communication, we reorganize the convolution algorithm to prefetch image regions to register, and to do more work per thread. Our algorithm works as follows. Each thread begins by prefetching a region of the image from off-chip memory into its registers. For example, when using a 3x3 convolution filter, we might prefetch a 4x4 region of the image into registers. Then, using a user-provided convolution filter that we store in the constant memory, we compute a region of output pixels. Finally, we write the output pixels back to off-chip memory. For the example with a 3x3 filter and 4x4 region in registers, each thread would produce four output pixels (see the right side of the figure below).

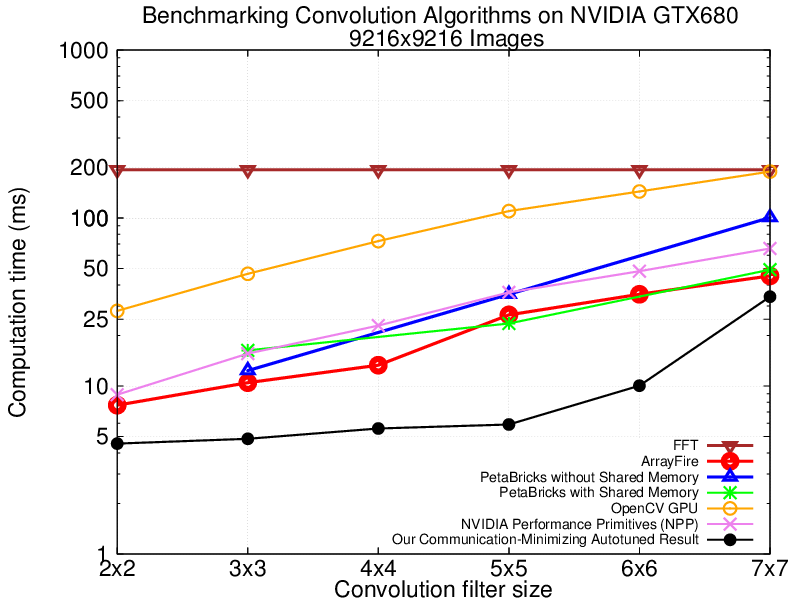
Our algorithm provides the following advantages. Explicit prefetching increases the compiler's freedom to overlap communication and computation. Further, doing more work per thread reduces the total number of memory accesses, it exploits the L1 cache on instruction replays, and it increases instruction-level parallelism. Now that we have discussed how and why our algorithm reduces the time spent in memory communication, we turn to the problem of sweeping the design space of implementation choices. We implement an autotuner that evaluates both the global memory and the texture cache for off-chip storage. We also evaluate the impact of first fetching an image region to shared memory, then distributing the pixels from shared memory to registers. Further, our autotuner sweeps the design space of thread granularities. Depending on filter size, our autotuner's speedups on NVIDIA Fermi and Kepler range from 1.2x to 4.5x over state-of-the-art GPU libraries. Further, we achieve the memory bound for 2x2 and 3x3 filters on Kepler, and we achieve within 2x of the memory bound for these filter sizes on Fermi. The following plot provides a comparison between our communication-minimizing results several other libraries on NVIDIA Kepler GTX680.
Some details:
- What is the scientific or engineering problem being solved?
- This work focuses on accelerating 2D image convolution with small filters, with feature extraction as a motivating application.
- What parallel platform has the application targeted? (distributed vs. shared memory, vector, etc.)
- This work targets vector-thread data parallel platforms; specifically single-GPU systems.
- What tools were used to build the application? (languages, libraries, etc.)
- The Berkeley ParLab and other groups have developed several tools and domain-specific languages (DSLs) for parallel image processing. However, in this work we program in plain CUDA, implementing some optimizations that do not appear to have been used in these DSLs. In the long run, we hope to propagate our optimizations into DSLs and libraries.
- How well did the application perform? How does this compare to the platform's best possible performance?
- Depending on filter size, our autotuner's speedups on NVIDIA Fermi and Kepler range from 1.2x to 4.5x over state-of-the-art GPU libraries. Further, for 2x2 and 3x3 convolution filters, we achieve the bandwidth bound on the NVIDIA Kepler architecture.
- If the application is run on a major supercomputer, where does that computer rank on the Top 500 list?
- So far, our focus has been optimizing single-GPU performance. However, the #1 computer on the Top500 list (Titan) uses a similar flavor of NVIDIA Kepler to those that we used in our experiments.
- Does the application "scale" to large problems on many processors? If you believe it has not, what bottlenecks may have limited its performance?
- The application is strongly memory bounded. One of our goals was actually to perform more work per thread, which is a bit counterproductive in terms of scaling. That said, even our ``more work per thread" implementations are able to saturate one GPU for 640x480 or larger images. Multi-GPU or cluster-scale implementations of convolution could be an interesting extension. However, the arithmetic intensity is low enough that communication across a cluster may become the dominating term in the computation time.