(These are notes adapted from a talk I gave at the Student Arithmetic Geometry seminar at Berkeley)
Introduction
Probably the most famous open problem in number theory is the Riemann hypothesis. In addition to being worth a million dollars, it is a deep and fundamental problem that has remained intractable since it was first proposed by Bernhard Riemann, in 1859.
The Riemann hypothesis springs out of the field of analytic number theory, which applies complex analysis to problems in number theory, often studying the distribution of prime numbers. The Riemann hypothesis itself has significant implications for the distribution of primes and implies an asymptotic statement about their density (for a precise statement, see here). But the Riemann hypothesis is usually formulated in the language of complex analysis, as a statement about a complex-analytic function, the Riemann zeta function, and its zeroes. This formulation is succint and elegant, and allows the problem to be subsumed into the larger study of the largely conjectural theory of L-functions.
This broader theory allows one to create analogues of the Riemann zeta function and Riemann hypothesis in other contexts. Often these “alternative Riemann hypotheses” are even harder than the original Riemann hypothesis, but there is a famous case where this is fortunately not true.
In the 1940’s, André Weil proved an analogue of the Riemann hypothesis: not for the Riemann zeta function, but for a different zeta function. Here’s one way to describe it: very roughly speaking, the Riemann zeta function is based on the field rational numbers  (it can be defined as an Euler product over the primes of ). Our zeta function will constructed analogously, but instead be based on the field
(it can be defined as an Euler product over the primes of ). Our zeta function will constructed analogously, but instead be based on the field  (the field of rational functions with coefficients in the finite field
(the field of rational functions with coefficients in the finite field  ). So instead of the number field , we have swapped it out and replaced it with a function field.
). So instead of the number field , we have swapped it out and replaced it with a function field.
Actually, what Weil proved, and what we will prove today, is the analogue of the Riemann hypothesis for global function fields. This work represents the greatest progress we have towards the original Riemann hypothesis, and serves as tantalizing evidence for it.
There is a general pattern in number theory which looks something like the following: start with a problem in number theory. Adapt the problem from the number field setting to the function field setting. Then interpret the function field as the function field of a curve (usually), and then use techniques of algebraic geometry (for example, is the function field of a line over ). That is exactly what we will do here: it will therefore look less like complex analysis and more like algebraic geometry
Math (somewhat rushed)
Let  be a smooth projective curve over a finite field . Let
be a smooth projective curve over a finite field . Let  be the set of
be the set of  points of
points of  Then the zeta function of is defined by
Then the zeta function of is defined by
![\[Z(C, T) = \exp \bigg(\sum_{r=1}^{\infty} N_r \frac{T^r}{r} \bigg).\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-cd792f705a3532be2b05801adabb9e80_l3.png "Rendered by QuickLaTeX.com")
Here, we are using  as a change of variables: if we plug in
as a change of variables: if we plug in  for , then we obtain an exactly analogous zeta function to the Riemann zeta function, except with respect to the function field of instead of the field . There are three important properties that we would like
for , then we obtain an exactly analogous zeta function to the Riemann zeta function, except with respect to the function field of instead of the field . There are three important properties that we would like  to have: (1) rationality, (2) satisfies a functional equation, and (3) satisfies an analogue of the Riemann hypothesis. Part (3) was proved by André Weil in the 1940’s; parts (1) and (2) were proved much earlier. In this post, I will present a proof of the analogue of the Riemann hypothesis assuming (1) and (2), along the lines of Weil’s original proof using intersection theory. All this material and much more is in an expository paper by James Milne called “The Riemann Hypothesis over Finite Fields: From Weil to the Present Day”. A useful reference is Appendix C in Hartshorne’s Algebraic Geometry; some material also comes from section V.1 on surfaces.
to have: (1) rationality, (2) satisfies a functional equation, and (3) satisfies an analogue of the Riemann hypothesis. Part (3) was proved by André Weil in the 1940’s; parts (1) and (2) were proved much earlier. In this post, I will present a proof of the analogue of the Riemann hypothesis assuming (1) and (2), along the lines of Weil’s original proof using intersection theory. All this material and much more is in an expository paper by James Milne called “The Riemann Hypothesis over Finite Fields: From Weil to the Present Day”. A useful reference is Appendix C in Hartshorne’s Algebraic Geometry; some material also comes from section V.1 on surfaces.
Let  be the genus of . Then (1) says that is a rational function of . The specific function equation of (2) is the following:
be the genus of . Then (1) says that is a rational function of . The specific function equation of (2) is the following:
![\[Z(C, \frac{1}{qT}) = q^{1-g}T^{2-2g} Z(C, T)\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-4e675f763db96169cf6387e4907ffed2_l3.png "Rendered by QuickLaTeX.com")
It turns out that we can write out  explicitly: there exist constants
explicitly: there exist constants  for
for  such that
such that
![\[Z(C, T) = \frac{(1- \alpha_1T) \cdots (1 - \alpha_{2g}T)}{(1-T)(1-qT)}\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-7d8f90b25caa82eb74e24af89a42f66c_l3.png "Rendered by QuickLaTeX.com")
and the functional equation implies that the constants can be rearranged if necessary so that

Now, the analogue of the Riemann hypothesis states the following:

(To see the connection between this statement and the ordinary Riemann hypothesis, check out this blog post by Anton Hilado)
Notice that, assuming rationality and the functional equation, the Riemann hypothesis will follow from simply the inequality  .
.
We will prove the Riemann hypothesis via the Hasse-Weil inequality, which is an inequality that puts an explicit bound on . The Hasse-Weil inequality states that

which is actually a pretty good bound. Why does the Hasse-Weil inequality imply the Riemann hypothesis? Well, if we take the logarithm of and use the power series for  , regrouping terms gives us
, regrouping terms gives us
 ; so
; so 
In other words,
 is bounded.
is bounded.
Letting  , we have
, we have
 , so
, so  for all
for all 
as desired. (check this works, even if are not distinct)
Proof of the Hasse-Weil inequality
We will prove the Hasse-Weil inequality using intersection theory. First, we will consider as a curve over  . Then there is the Frobenius map
. Then there is the Frobenius map  . If we embed into projective space, then
. If we embed into projective space, then  sends
sends ![[x_0 : \cdots : x_n] \mapsto [x_0^{q_r} : \cdots : x_n^{q^r}]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-38e48e49691612d94147383afe65e570_l3.png "Rendered by QuickLaTeX.com") . We can interpret as the size of the set of fixed points of . Our plan then to use inequalities from intersection theory to bound the intersection of
. We can interpret as the size of the set of fixed points of . Our plan then to use inequalities from intersection theory to bound the intersection of  and
and  (the diagonal) in
(the diagonal) in  .
.
First, let us set up the intersection theory we need. This material is from Chapter V.1 of Hartshorne, on surfaces.
Intersection pairing on a surface: Let  be a surface. There exists a symmetric bilinear pairing
be a surface. There exists a symmetric bilinear pairing  (where the product of divisors and
(where the product of divisors and  is denoted
is denoted  ) such that if
) such that if  are smooth curves intersecting transversely, then
are smooth curves intersecting transversely, then
 .
.
Furthermore, another theorem we’ll need is the Hodge index theorem:
Let  be an ample divisor on and a nonzero divisor, with
be an ample divisor on and a nonzero divisor, with  . Then
. Then  . (
. ( denotes
denotes  )
)
Now let us begin with some general set up. Let  and
and  be two curves, and let
be two curves, and let  . Identify with
. Identify with  and with
and with  . Notice that
. Notice that  and
and  . Thus
. Thus  .
.
Let be a divisor on . Let  and
and  ; also,
; also,  (expand it out). The Hodge index theorem implies then that
(expand it out). The Hodge index theorem implies then that  . Expanding this out yields
. Expanding this out yields  . This fundamental inequality is called the Castelnuovo-Severi inequality. We may define
. This fundamental inequality is called the Castelnuovo-Severi inequality. We may define  .
.
Next, let us prove the following inequality: if and  are divisors, then
are divisors, then

Proof (fill in details): Expand out  , for
, for  . We can let
. We can let  become arbitrarily close to
become arbitrarily close to  , yielding the inequality.
, yielding the inequality. 
Here’s another lemma we will need: Consider a map  . If
. If  is the graph of
is the graph of  on
on  , then
, then  (where
(where  is the genus of ).
is the genus of ).
Proof (fill in details): Rearrange adjunction formula.
Now we have what we need: we will do intersection theory on . The Frobenius map  is a map of degree
is a map of degree  , so
, so  . We might as well think of as the graph of the identity map, so
. We might as well think of as the graph of the identity map, so  . Finally,
. Finally,  and
and  . Plugging it into the inequality, we get
. Plugging it into the inequality, we get

yielding the Hasse-Weil inequality

This proves the Riemann hypothesis for function fields, or equivalently the Riemann hypothesis curves over finite fields.
The Weil conjectures
After Weil proved this result, he speculated whether analogous statements were true for not only curves over finite fields, but higher-dimensional algebraic varieties over finite fields. He proposed as conjectures that the zeta functions for such varieties should also satisfy (1) rationality, (2) a functional equation, and (3) an analogoue of the Riemann hypothesis.
Weil also speculated a connection with algebraic topology. In our work above, the genus was crucial. But the genus can alternatively be defined topologically, by taking the equations that define the curve, looking at the locus they cut out when graphed over the complex numbers, and counting how many holes the resulting shape has. Weil suggested that for arbitrary varieties, topological Betti numbers should play this role: that is, the zeta function of the variety over the finite field should be closely connected with the topology of the analogous variety over the complex numbers.
There’s an interesting blog post that discusses this idea, in our context of curves. But the rest is history. The story of the Weil conjectures is one of the most famous in all of mathematics: the effort to prove them revolutionized algebraic geometry and number theory forever. The key innovation was the theory of étale cohomology, which is an analogue of classical singular cohomology for algebraic varieties over arbitrary fields.
 is a cover of a topological space
is a cover of a topological space  on
on  into a function on all of
into a function on all of  for all pairs
for all pairs  , then they glue uniquely to a function
, then they glue uniquely to a function  .
. be the disjoint union of the
be the disjoint union of the  . Combine the
. Combine the 
 and
and  . Then for the
. Then for the  as functions on
as functions on  (think about this!). We’ll return to this later. Now, let’s step up one level, from functions to vector bundles.
(think about this!). We’ll return to this later. Now, let’s step up one level, from functions to vector bundles. to a vector bundle
to a vector bundle  ? We also know the answer to this: transition maps satisfying the cocyle condition. More precisely, we need for each pair
? We also know the answer to this: transition maps satisfying the cocyle condition. More precisely, we need for each pair  restricted to
restricted to  , such that for every triple
, such that for every triple  ,
,  on the triple intersection
on the triple intersection  .
. together as a single vector bundle
together as a single vector bundle  . What we’re trying to do is “descend” this vector bundle over
. What we’re trying to do is “descend” this vector bundle over  . It has three projections down to
. It has three projections down to 
 .
.  of vector bundles, and the cocycle condition translates to
of vector bundles, and the cocycle condition translates to 
 which assigns to every base object the set of (insert adjective) functions on it. Then such a functor (presheaf) is a sheaf if, for every function on
which assigns to every base object the set of (insert adjective) functions on it. Then such a functor (presheaf) is a sheaf if, for every function on  , is pulled to identical functions, is the unique pullback of a function on
, is pulled to identical functions, is the unique pullback of a function on  is the equalizer
is the equalizer  .
. , and a truth value on
, and a truth value on  (the truth value is whether the “functions” agree).
(the truth value is whether the “functions” agree). , and these isomorphisms, pulled back to
, and these isomorphisms, pulled back to  (along the three projections
(along the three projections  ), satisfy a cocyle condition. If such a thing made sense, we might say
), satisfy a cocyle condition. If such a thing made sense, we might say 
 , and truth value on
, and truth value on  . Each morphism of
. Each morphism of  . A morphism of
. A morphism of  .
. , say
, say  where
where  is a tiny number, then the determinant changes approximately by
is a tiny number, then the determinant changes approximately by  times
times  . Here
. Here  stands for the identity matrix.
stands for the identity matrix.  be either
be either  or
or  (so we are working with real or complex Lie groups; but of course, everything makes sense for algebraic groups over arbitrary fields). Then there is a morphism of Lie groups called the determinant
(so we are working with real or complex Lie groups; but of course, everything makes sense for algebraic groups over arbitrary fields). Then there is a morphism of Lie groups called the determinant  , given by sending a matrix to its determinant. Since we are restricting to invertible matrices, the determinants are nonzero. To check that this is really a morphism of Lie groups (i.e. both a smooth map and a homomorphism of groups), note that the determinant map is a polynomial map in the entries of the matrix (and therefore smooth) and is a group homomorphism by the property that
, given by sending a matrix to its determinant. Since we are restricting to invertible matrices, the determinants are nonzero. To check that this is really a morphism of Lie groups (i.e. both a smooth map and a homomorphism of groups), note that the determinant map is a polynomial map in the entries of the matrix (and therefore smooth) and is a group homomorphism by the property that  .
. , there is an induced linear map on from the tangent space of
, there is an induced linear map on from the tangent space of  to the tangent space of
to the tangent space of  called the derivative of
called the derivative of  , the Lie algebra at the identity matrix is called
, the Lie algebra at the identity matrix is called  . We can think of it as consisting of all
. We can think of it as consisting of all  matrices, and the bracket operation is defined by
matrices, and the bracket operation is defined by ![[A, B] = AB - BA](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-3e92bd90a1cd49ae3759b72c269f4199_l3.png "Rendered by QuickLaTeX.com") . The Lie algebra of
. The Lie algebra of  at
at  , the derivative of the determinant at the identity, is actually the trace. That is, it sends a matrix to its trace, the sum of the entries on the diagonal. Note that since it is a homomorphism of Lie algebras, it preserves the bracket, and we recover the familiar property of trace
, the derivative of the determinant at the identity, is actually the trace. That is, it sends a matrix to its trace, the sum of the entries on the diagonal. Note that since it is a homomorphism of Lie algebras, it preserves the bracket, and we recover the familiar property of trace  , so
, so  .
. directly, since it is an open subset of a vector space. Let
directly, since it is an open subset of a vector space. Let  be a matrix; then the derivative at the identity evaluated at
be a matrix; then the derivative at the identity evaluated at ![\[\lim_{t \to 0} \frac{\det(1+t\phi) - 1}{t}.\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-98538ba3f528363ed6d131450219ef84_l3.png "Rendered by QuickLaTeX.com")
 is a polynomial in
is a polynomial in  , and the number we’re looking for is the coefficient of the
, and the number we’re looking for is the coefficient of the ![\[\det(1 + t\phi) (e_1 \wedge \cdots \wedge e_n) = (e_1+\phi(e_1)t)\wedge(e_2+\phi(e_2)t)\wedge \cdots \wedge (e_n+\phi(e_n)t).\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-e1724fbcc893d7c6c599390bde7da400_l3.png "Rendered by QuickLaTeX.com")
 . Then
. Then ![\[(e_1+\phi(e_1)t)\wedge(e_2+\phi(e_2)t)=e_1\wedge e_2 + (\phi(e_1)\wedge e_2 + e_1 \wedge \phi(e_2))t + (\phi(e_1)\wedge \phi(e_2)) t^2.\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-91d1ec9680cf52074eb5798ef408f395_l3.png "Rendered by QuickLaTeX.com")
 ,
, ![\[(e_1+\phi(e_1)t)\wedge(e_2+\phi(e_2)t)\wedge(e_3+\phi(e_3)t)\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-6d48a66d146fe3a5abee0bfb48236720_l3.png "Rendered by QuickLaTeX.com")
![\[=e_1\wedge e_2\wedge e_3\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-16d5a0f1361e6b870da8b42a654ac024_l3.png "Rendered by QuickLaTeX.com")
![\[+ (\phi(e_1)\wedge e_2 \wedge e_3 + e_1 \wedge \phi(e_2) \wedge e_3 + e_1 \wedge e_2 \wedge \phi(e_3))t\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-b75e36a7b3c2aa03dd3dc889d0d7ed4d_l3.png "Rendered by QuickLaTeX.com")
![\[+ (\phi(e_1)\wedge \phi(e_2) \wedge e_3 + \phi(e_1)\wedge e_2) \wedge \phi(e_3) + e_1\wedge \phi(e_2) \wedge \phi(e_3)) t^2\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-697a1450ba2e9ccc4d1c33ed3be5e5cf_l3.png "Rendered by QuickLaTeX.com")
![\[+ (\phi(e_1)\wedge \phi(e_2) \wedge \phi(e_3)) t^3.\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-5cf71d69283ddc0966b7aa1b7879823e_l3.png "Rendered by QuickLaTeX.com")
 . (In fact, see if you can convince yourself that the coefficient of
. (In fact, see if you can convince yourself that the coefficient of  is
is  .)
.) and
and  . This sort of thing is usually left as an exercise (especially the first Corollary) and not proved in full generality in algebra courses, although it is not hard.
. This sort of thing is usually left as an exercise (especially the first Corollary) and not proved in full generality in algebra courses, although it is not hard. is a commutative ring with identity and
is a commutative ring with identity and  and
and  are ideals of
are ideals of  , there is a natural map
, there is a natural map  .
. is an isomorphism of
is an isomorphism of  as an
as an  , since the map is a ring homomorphism. To see injectivity, notice that every element
, since the map is a ring homomorphism. To see injectivity, notice that every element ![\[\sum_{i=1}^n [a_i]\otimes[b_i] \in R/I \otimes R/J \ \ (a_i, b_i \in R)\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-e36ddab93c0d892cf1225624cb175c74_l3.png "Rendered by QuickLaTeX.com")
![[c]\otimes 1 = 1 \otimes [c]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-295cecaf22f5170d6a38248abbbf4121_l3.png "Rendered by QuickLaTeX.com") where
where  . If
. If ![[c] \otimes 1 \mapsto 0](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-ab5503fffe294e96ebe3f3a2b9cc2fc7_l3.png "Rendered by QuickLaTeX.com") , then
, then  . So
. So  ,
,  . Then
. Then ![[c]\otimes1=[i+j]\otimes1=[i]\otimes1+1\otimes[j]=0+0=0](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-f1e95c5376c1788264577dc6057870f4_l3.png "Rendered by QuickLaTeX.com") .
.

 is injective. If
is injective. If  , it is also surjective, and thus an isomorphism.
, it is also surjective, and thus an isomorphism.![[c]\mapsto(0,0)](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-6929375e920b09edf2cf7cf6fcde9646_l3.png "Rendered by QuickLaTeX.com") , then
, then  and
and  , so
, so  so
so ![[c]=0\in R/(I\cap J)](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-e21d08dc987bc124ddbd09d191008e74_l3.png "Rendered by QuickLaTeX.com") . To see surjectivity, note that
. To see surjectivity, note that  ,
,  , such that
, such that  , for any
, for any  . Consider
. Consider ![([a], [b]) \in R/I\times R/J](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-6091c871b260e4635fbd295f813745f7_l3.png "Rendered by QuickLaTeX.com") , and set
, and set  . Then
. Then  , so
, so ![a+i \mapsto ([a],[b])](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-7c71b30a42544411df1bfe176281b4b1_l3.png "Rendered by QuickLaTeX.com") .
. ,
,  . In particular, by applying this repeatedly we have
. In particular, by applying this repeatedly we have  .
. , then
, then  .
. . To go the other way, note that
. To go the other way, note that  ,
,  , and
, and  such that
such that  . So, consider an element
. So, consider an element  . Then we have
. Then we have  . Since
. Since  ,
,  , and since
, and since  ,
,  . So
. So  .
. , and when
, and when  this Tor group vanishes.
this Tor group vanishes. ,
,  , where
, where  is the transpose of
is the transpose of 
 is the set of permutations of the set
is the set of permutations of the set  , and
, and  is the
is the  . This formula is derived from the definition of the determinant via exterior algebra. One can check by hand that this gives the familiar expressions for the determinant when
. This formula is derived from the definition of the determinant via exterior algebra. One can check by hand that this gives the familiar expressions for the determinant when  .
. , we have
, we have

 . Then the product inside the summation is
. Then the product inside the summation is
 , our expression simplifies to
, our expression simplifies to 
 s with
s with  . So
. So  satisfying the following axioms:
satisfying the following axioms: if and only if
if and only if 

 (triangle inequality)
(triangle inequality) .
. is Archimedean if, for
is Archimedean if, for  ,
,  ,
,  for some natural number
for some natural number  .
. to obtain
to obtain  . In other words, we can write the definition equivalently as:
. In other words, we can write the definition equivalently as: ,
,  for some natural number
for some natural number  takes the place of
takes the place of  . The important thing here is that
. The important thing here is that  So what this is saying is that, given any element of the field, there is some natural number that beats it.
So what this is saying is that, given any element of the field, there is some natural number that beats it. for all nonzero
for all nonzero  . So, either
. So, either  or
or  . Thus by taking arbitrarily high powers of
. Thus by taking arbitrarily high powers of  , we can obtain arbitrarily high absolute values. So we can reformulate the definition as follows:
, we can obtain arbitrarily high absolute values. So we can reformulate the definition as follows: contains arbitrarily large elements.
contains arbitrarily large elements. is bounded. However, if any
is bounded. However, if any  , then taking arbitrarily high powers of
, then taking arbitrarily high powers of  for
for  .
. .
. are positive real numbers, if you add
are positive real numbers, if you add  where
where  , there exists a natural number
, there exists a natural number  .
. . We can order rational functions by declaring that
. We can order rational functions by declaring that if
if  as
as 
 . In other words, we order rational functions by looking at their asymptotic behavior. One can check that this satisfies the axioms, making
. In other words, we order rational functions by looking at their asymptotic behavior. One can check that this satisfies the axioms, making  an ordered field.
an ordered field.![\[p(x) = \frac{f(x)}{g(x)} = \frac{a_nx^n + \cdots + a_1x + a_0}{b_mx^m + \cdots + b_1x + a_0}\]](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-f37739069bd6500bac36569aac0ac183_l3.png "Rendered by QuickLaTeX.com")
 ) if and only if
) if and only if  .
. , no matter how many times we add it to itself, it will never surpass
, no matter how many times we add it to itself, it will never surpass  : the function
: the function  is eventually surpassed by
is eventually surpassed by 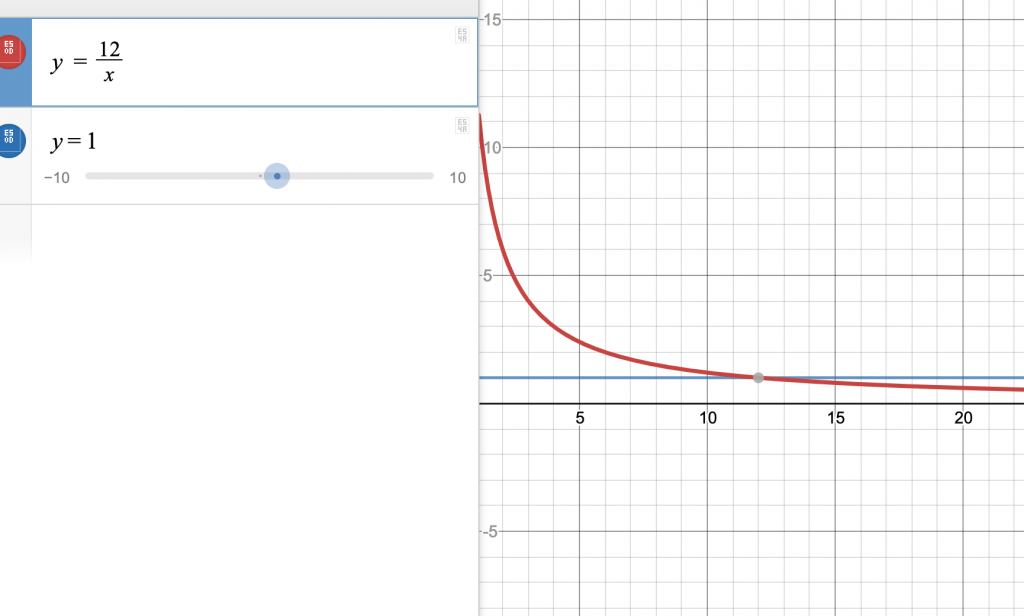
 , show there exists an integer
, show there exists an integer  if and only if degree
if and only if degree degree
degree .
. if some multiple of
if some multiple of  goes off to infinity.
goes off to infinity. , and
, and 

 . However, given a cubic form
. However, given a cubic form  corresponds to the same curve. Furthermore, if all the coefficients are zero, then the form doesn’t correspond to the curve at all. Thus the space of plane cubics is nine-dimensional projective space.
corresponds to the same curve. Furthermore, if all the coefficients are zero, then the form doesn’t correspond to the curve at all. Thus the space of plane cubics is nine-dimensional projective space.  in this space
in this space  of plane cubics. This geometric result corresponds to the following purely algebraic fact:
of plane cubics. This geometric result corresponds to the following purely algebraic fact: satisfies property
satisfies property  ” this means that
” this means that  says that the subset of
says that the subset of  for which P(x) holds is dense in
for which P(x) holds is dense in  . We can construct a morphism
. We can construct a morphism
 to their product
to their product  . This map is (in general) 6 to 1, since there are 6 permutations of three (distinct) linear forms.
. This map is (in general) 6 to 1, since there are 6 permutations of three (distinct) linear forms.

![A(\mathbb{P}^9) \cong \mathbb{Z}[x]/(x^{10})](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-24d3a4d0666872689c4bc198a797d090_l3.png "Rendered by QuickLaTeX.com") and
and ![A(\mathbb{P}^2 \times \mathbb{P}^2 \times \mathbb{P}^2) \cong \mathbb{Z}[a, b, c]/(a^3, b^3, c^3)](https://www.ocf.berkeley.edu/~rohanjoshi/wp-content/ql-cache/quicklatex.com-9e0515327e9dfa6e4e3a61048b6a64b3_l3.png "Rendered by QuickLaTeX.com") . The class of any
. The class of any  is
is  . Furthermore,
. Furthermore,  . So,
. So,  . If we expand this out, removing every term that has any variable to a power of three or greater, we see that every term except the monomial term of
. If we expand this out, removing every term that has any variable to a power of three or greater, we see that every term except the monomial term of  vanishes, and its coefficient is the
vanishes, and its coefficient is the  .
.  is the the number of ordered triples of linear forms which correspond to cubic forms contained in a general web. Dividing by six, since six ordered triples correspond to one unordered triple (i.e. one distinct triangle), we obtain our answer of 15.
is the the number of ordered triples of linear forms which correspond to cubic forms contained in a general web. Dividing by six, since six ordered triples correspond to one unordered triple (i.e. one distinct triangle), we obtain our answer of 15. be a noetherian local domain where
be a noetherian local domain where  Then
Then  .
. . Then
. Then  for all
for all  . So for all
. So for all  . Since
. Since  .
. . This eventually stabilizes for high enough
. This eventually stabilizes for high enough  . Thus
. Thus  , so
, so  . But
. But  is a unit, so
is a unit, so  , so
, so  .
.  be a noetherian local ring where
be a noetherian local ring where  and
and  is not nilpotent. Then
is not nilpotent. Then  be the ideal of elements that kill some power of
be the ideal of elements that kill some power of  to refer to elements of
to refer to elements of  for some fixed
for some fixed  .
. . Thus
. Thus  .
. . Since
. Since  can be written as
can be written as  . But recall that
. But recall that  . So
. So  so
so  .
.  . If we force
. If we force  , so
, so  is algebraic (e.g. the polynomial
is algebraic (e.g. the polynomial  );
);  );
);  are not. (A complex number that is not algebraic is called transcendental)
are not. (A complex number that is not algebraic is called transcendental)  (or
(or  ) as a root, for algebraic numbers
) as a root, for algebraic numbers  and
and  . That is the subject of this post. Instead of trying to formally prove the result, I will illustrate the approach for a specific example: showing
. That is the subject of this post. Instead of trying to formally prove the result, I will illustrate the approach for a specific example: showing  is algebraic.
is algebraic. . We will think of this as a four-dimensional vector space, where the scalars are elements of
. We will think of this as a four-dimensional vector space, where the scalars are elements of  . Every element can be uniquely expressed as
. Every element can be uniquely expressed as  , for
, for  .
. defined as “multiply by
defined as “multiply by  which maps
which maps  . This is definitely a linear map, since it satisfies
. This is definitely a linear map, since it satisfies  and
and  . In particular, we should be able to represent it by a matrix.
. In particular, we should be able to represent it by a matrix. ,
,  ,
,  , and
, and  . Thus we can represent
. Thus we can represent  .
. of this matrix, which is defined as
of this matrix, which is defined as  , is
, is  , which has
, which has  is the zero matrix. But the matrix we get when plugging
is the zero matrix. But the matrix we get when plugging  ; thus
; thus  .
. in general, why is it finite-dimensional, etc. This constructive method, which assumes the Cayley-Hamilton theorem, only replaces the non-constructive “linear dependence” argument in Proposition 4 of
in general, why is it finite-dimensional, etc. This constructive method, which assumes the Cayley-Hamilton theorem, only replaces the non-constructive “linear dependence” argument in Proposition 4 of