alpha-beta(player,board,alpha,beta)
if(game over in current board position)
return winner
children = all legal moves for player from this board
if(max's turn)
for each child
score = alpha-beta(other player,child,alpha,beta)
if score > alpha then alpha = score (we have found a better best move)
if alpha >= beta then return alpha (cut off)
return alpha (this is our best move)
else (min's turn)
for each child
score = alpha-beta(other player,child,alpha,beta)
if score < beta then beta = score (opponent has found a better worse move)
if alpha >= beta then return beta (cut off)
return beta (this is the opponent's best move)
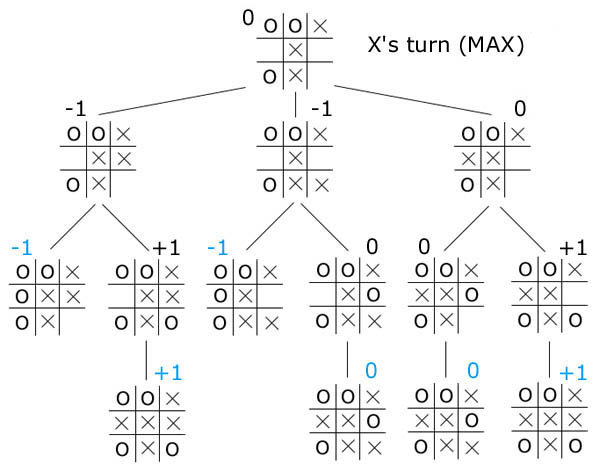
Notice that it is to our advantage to generate the best moves first for max
and the worst moves first for min; this will cause the algorithm to cut off
more quickly. On average, using a good successor generator will allow
alpha-beta to search to a level twice as deep as minimax in the same amount
of time. Note also that alpha-beta returns the same score as minimax; it
simply returns the same result in faster time.