
Review Analysis — reviews.json
I now faced a much larger problem. The business.json file was relatively small, only a couple hundred megabytes of data, but now we are dealing with a datafile that is several gigabytes large. This data processing was something I could no longer do locally, due to memory constraints, and thus I needed to turn towards utilizing online Kernels. Both Kaggle Kernels utilized are linked to the side of this page.
Even with the usage of Kaggle Kernels, the dataset was just too large to even be processed into the notebook. The dataset contained over 6,000,000 reviews, and we needed to filter out those that we were interested in: reviews for the various McDonald’s locations across the Las Vegas area. A seemingly simple task, but an iterative approach to the data processing was necessary, in order to ensure that the data wasn’t just simply thrown into the RAM. A slower approach indeed, but it was the only one that would work given the memory constraints of the notebooks I was using.
count = 0
filename = '../input/review.json'
with open(filename, 'r') as f:
data = {}
for line in f:
d = json.loads(line)
if d['business_id'] in business_ids:
data[count] = d
count += 1Now that our reviews are filtered and cleaned up, we can start analyzing the reviews for each business! To get a sense of what the reviews were saying I found that Word Clouds may come in handy for this purpose. Although very simple in nature, I believe that WordClouds are able to effectively illustrate and summarize a dataset such as this. For our Word Clouds, the larger in size a word, the higher its frequency of appearance in the text. Color has no significant meaning for our purposes.
def generate_wordcloud(business_id, stars=np.arange(1, 6)):
stopwords = set(STOPWORDS)
stopwords.update(['McDonald\'s', 'McDonald', 'McDonalds'])
text = get_reviews(business_id, stars)
wordcloud = WordCloud(stopwords=stopwords, width=800, height=400, background_color='white', max_words=100).generate(text)
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
With these Word Clouds, we are now able to quickly summarize a businesses reviews and visualize them, an extremely useful tool for the comparisons that we are looking at. After generating a few more WordClouds and layering them onto our previous Social Explorer map, we get the following map.
With these Word Clouds, we are able to get a better sense of the divide between the locations of McDonald’s. For the leftmost location — The Strip McDonald’s –, we see that it has an average rating of 3.5 stars, and the reviews for this location frequently use words like “great”, “good”, and “delicious”. The uppermost location — we’ll call this the Paradise Rd. McDonald’s — we get a very different picture, despite it being a mere 2 miles from location on The Strip. This location has an average rating of 1.5 stars, and reviews for this location frequently use words like “worst”, “wait”, “never”, and “rude”. And finally, for the lowermost location — we’ll denote as the Maryland Ave. McDonald’s –, we see that it also has an average rating of 1.5 stars, with words like “worst”, “horrible”, “rude”, “dirty”, and “never”. Essentially, the McDonald’s location on The Strip is receiving much better reviews than the McDonald’s locations that are right down the street.
To get a better sense of the sentiment of the reviews for each of the locations, I found the use of natural language processing to be a very natural inclusion for this assignment. Utilizing VADER Sentiment Analysis, we are able to analyze the sentiment — essentially, how “positive” or “negative” a review is — for each of the reviews for different locations, based on the number of stars that that review gave. The VADER algorithm will look at each word in a review, and each word has a sentiment score: either positive, negative, or neutral. We will be using the compound score, which ranges from -1 to 1, in order to normalize the scores for our reviews. We define a function as such.
def get_score(business_id, stars=np.arange(0, 6)):
analyzer = SentimentIntensityAnalyzer()
scores = []
for review in reviews[(reviews['business_id'] == business_id) & (reviews['stars'].isin(stars))]['text'].values:
scores = np.append(scores, analyzer.polarity_scores(review)['compound'])
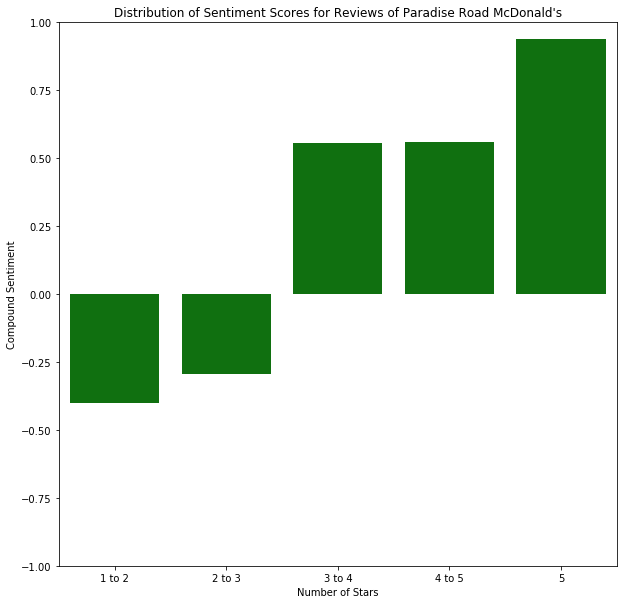
return np.mean(scores)Paradise Road McDonald’s — 1.5 Stars Average
The VADER compound score is shown in the caption of the image, ranging from -1 (very negative) to 1 (very positive).
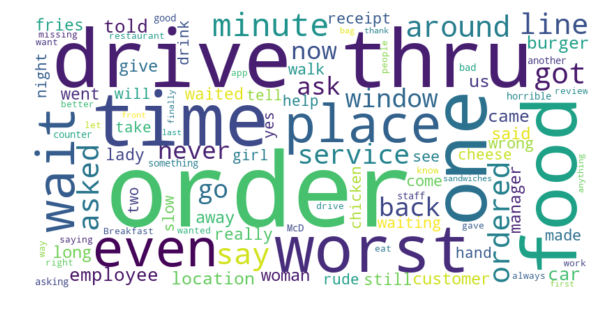
1 to 2 stars: -0.4016 
2 to 3 stars: -0.2925 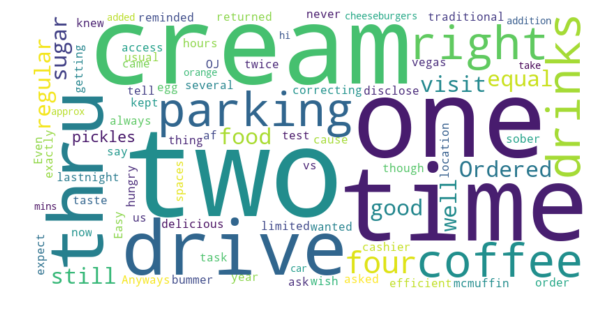
3 to 4 stars: 0.5567 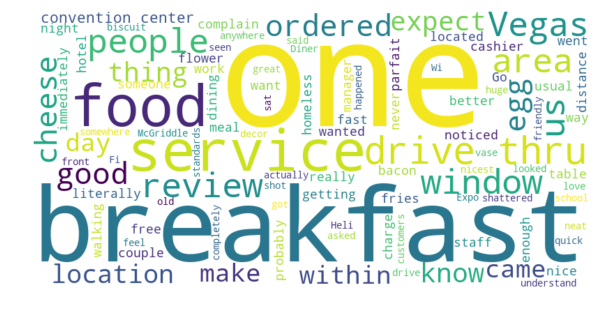
4 to 5 stars: 0.5589 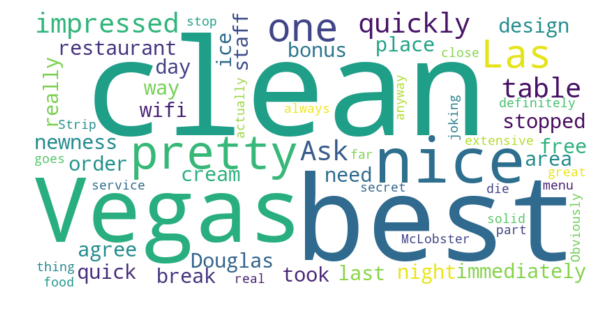
5 stars: 0.9398
Naturally, we see the progression of the sentiment score increasing as the ratings get better and better. We also can see within the Word Cloud the different words that people are using to describe the location. Something interesting to note is that even ratings that are in the 4 to 5 star range do not have a strong positive sentiment, it is virtually the same as the sentiment of 3 to 4 star reviews.
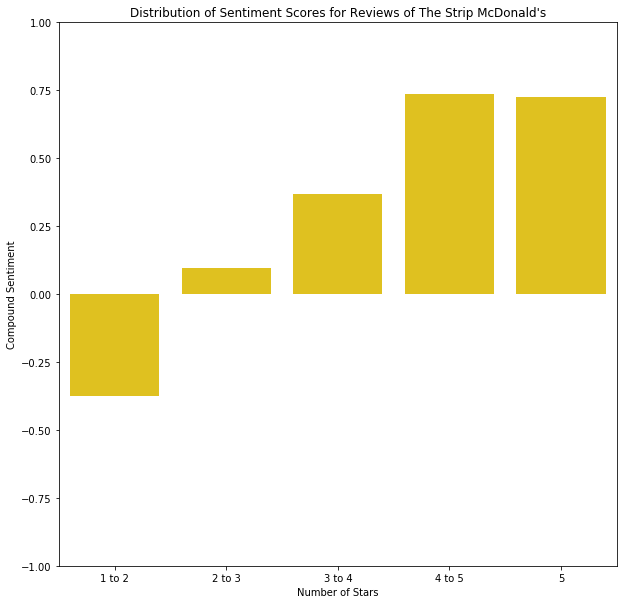
The Strip McDonald’s — 3.5 Stars Average
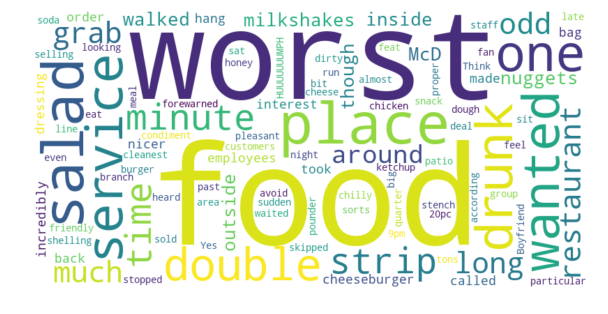
1 to 2 stars: -0.3752 
2 to 3 stars: 0.0948 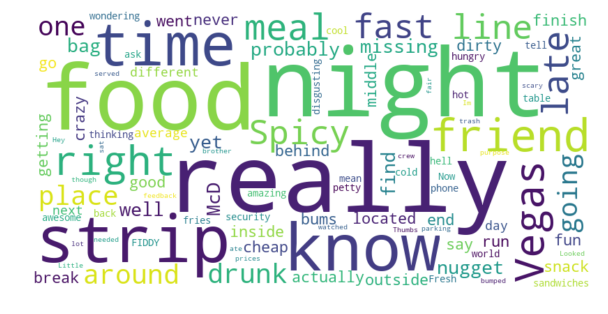
3 to 4 stars: 0.3696 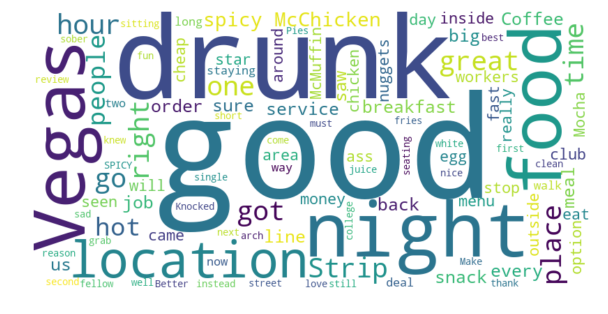
4 to 5 stars: 0.7376 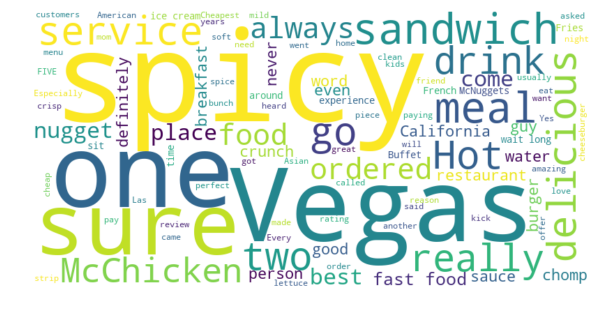
5 stars: 0.7262
For The Strip McDonald’s we see again a natural increase of sentiment scores as the ratings get better, but there is a slight dip for reviews that are 5 stars. We also see that the positive reviews are rated as more positive, and the negative reviews are not rated as negative as those for the Paradise Road McDonald’s.
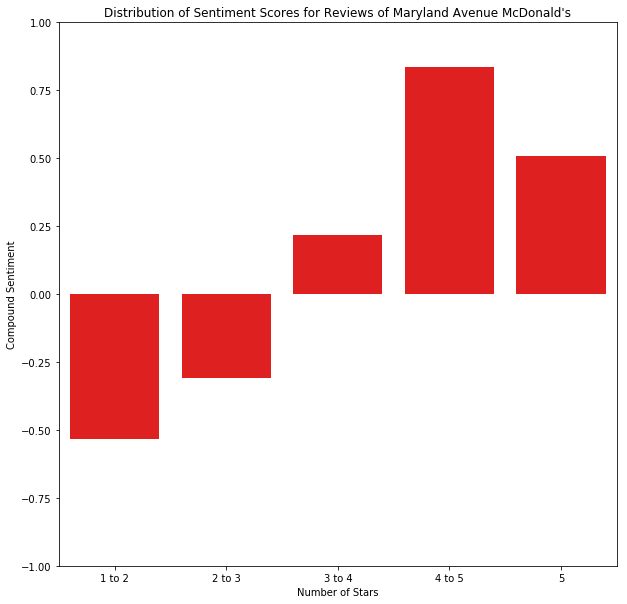
Maryland Avenue McDonald’s — 1.5 Stars Average

1 to 2 stars: -0.5336 
2 to 3 stars: -0.3086 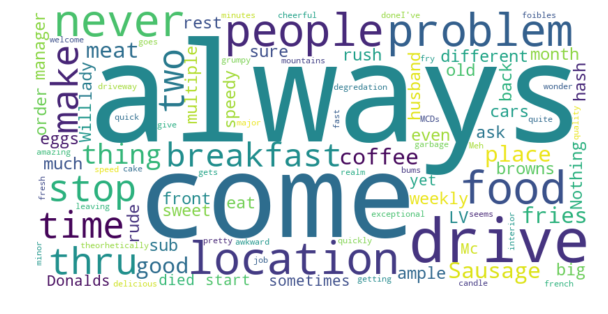
3 to 4 stars: 0.2155 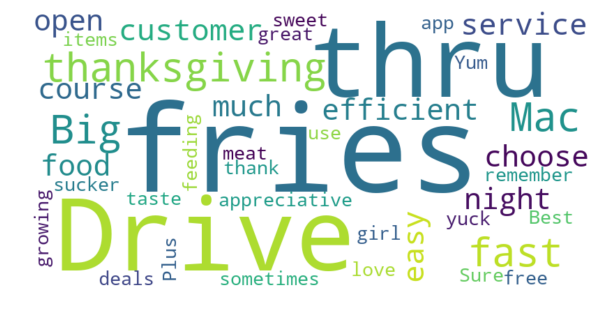
4 to 5 stars: 0.8344 
5 stars: 0.5073
The distribution of the sentiments for the Maryland Avenue location are a bit different, and we see that the 5 star reviews for this location have a lower sentiment rating than the sentiments for 4 to 5 star reviews. An interesting anomaly, but could be due to the sample size of reviews to draw from this location.
Distribution of Sentiments
Comparing the distributions of the sentiments, we see that the distribution for The Strip McDonald’s is shifted to the right, most evident in the sentiment scores for low rating reviews. For example, in both Paradise Road and Maryland Avenue locations, the sentiment scores for 1 to 3 star reviews are negative, implying that they have, on average, negative sentiment about the location. For The Strip location, the sentiment score for the 2 to 3 star reviews is neutral, positive leaning, meaning reviewers are less harsh in their reviews of this location for that rating bucket.