
Boundaries
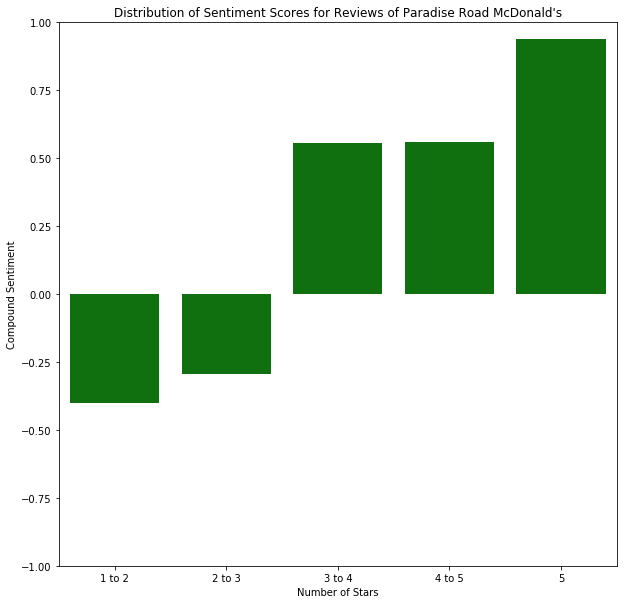
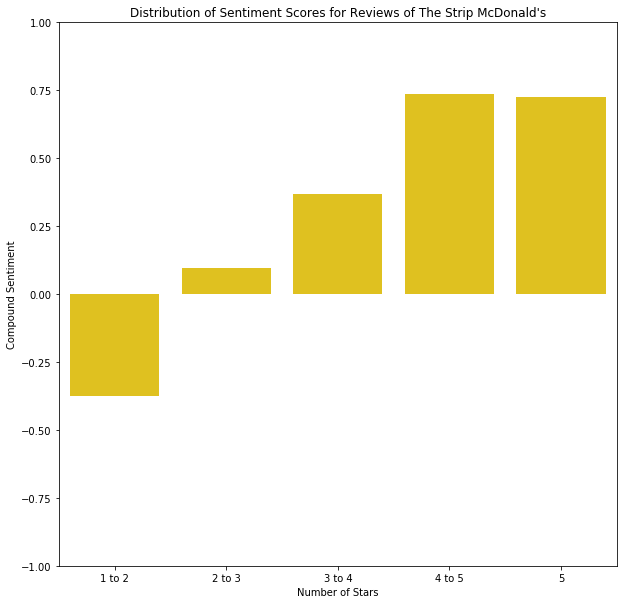
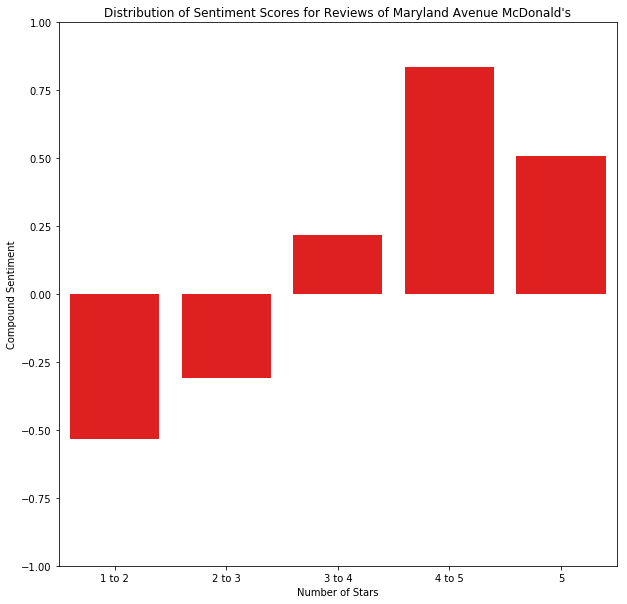
These distributions of sentiments tell us something about how reviews are distributed spatially. The business that these users are reviewing is the same in all scenarios: a simple McDonald’s that offers the same menu and price range, for all people in the area, including tourists and locals alike. Thus, the biggest difference between these McDonald’s is their location — where they are placed spatially within a community.
In looking at this map, we see that the divide is represented demographically, and we see remnants of that divide in the distribution of the sentiment scores. Further analyzing these boundaries, I found it quite interesting to look at predictions for business across the area. Focusing specifically on this same region near The Strip, I performed a k-Nearest Neighbors algorithm to predict the rating a business would get, based upon its relative position to other businesses. Note that we are now including all businesses, not just McDonald’s locations. This method of k-Nearest Neighbors was adapted from sklearn’s documentation of k-Nearest Neighbors.
X = np.array(vegas[['longitude', 'latitude']]) * 1000000
y = np.array(vegas[['stars']]).flatten() * 10
clf = neighbors.KNeighborsClassifier(n_neighbors=15, weights=weights)
clf.fit(X, y)
...
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])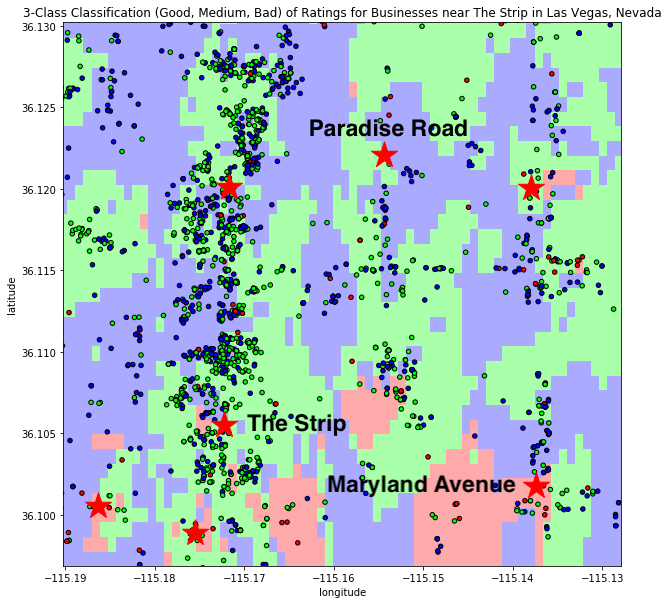
Looking at the predictions of ratings for these McDonald’s locations, we see that both The Strip and Maryland Avenue were predicted relatively well to be in their respective classifications (good and bad ratings on average, respectively). Paradise Road, however, appears to be an anomaly.
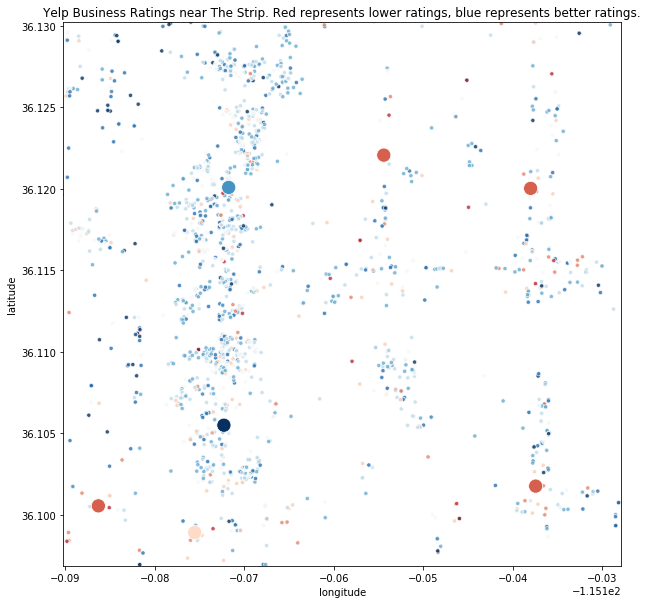
Looking at our original dataset for the ratings of businesses, we see that the Paradise Road McDonald’s is in an area where businesses generally receive okay reviews from Yelp users. Why is this location receiving such negative reviews then? Recall that the mean rating for this McDonald’s location is 1.5 stars.
Unfortunately, due to the nature of the data, as well as other confounding factors, we are unable determine any correlation between what could be causing this sudden drop in reviews. Through our explorative data analysis, however, we have been able to pinpoint this unique location and establish it as an anomaly, calling for possible future investigation.
However, in exploring this dataset, we have made some interesting conclusions. We know that specifically for this area, the spatial environment that a business is in will affect its reviews and its ratings. This confirms something that is seen throughout developments, both commercial and residential: location, location, location. Utilizing our analysis, we know that if a new McDonald’s were to open — again, ignoring any confounding factors and major differences between businesses –, we would be able to predict how it preforms in an area based on its spatial environment. Would we be completely accurate? Of course not! But these are the beginning steps of truly applied urban data analytics.
An Aside on Ethics
In utilizing this data, we need to understand that it is data sourced from the individual. When a user enters a review on Yelp, they are publicly posting their own opinion and rating for a business, and is essentially giving Yelp access to that data. These reviews are not anonymous — each reviews has a unique review ID, as well as the reviewers user ID attached to it. Yelp’s privacy policy states that in posting content on their website, you are doing so for public consumption, and essentially, all publicly posted material is free-range (including reviews, photos, and identity of the reviewer). The Yelp dataset is also open access for any academic or educational purposes, such as this assignment.
But in the wider picture, as data becomes more and more incorporated in our lives, we must learn to adapt with it and face the challenges that data presents. Big data and open data can be used for good, yes, but in the same sense, they can be used for bad. Redlining and spatial discrimination is now becoming a more prevalent issue, and as the next generation of data scientists, it is up to us to think critically about how to mitigate these negative byproducts of big data. So yes, collect on and innovate through these new data sources, but we must always recognize the consequences.